NextJS as BFF

💟 for building products!
Overview
Backend for frontend is a vast concept. From software architecture to engineering org structure, it has a big impact. In this post we are going to look at three things:
Why NextJS is good choice for BFF.
How to simplify contract between NextJS and Downstream services.
How another level of indirection makes the clean API.
Brief about BFF
The Backend for Frontend architecture is preferred when you have multiple clients like web app & mobile apps(iOS, Android), where each client provides a unique user experience. For example, the experience that we expect as users from native app is different from the web app.
In the below diagram, we can see that in traditional architecture there’s a single Backend that serves both mobile and web client. In the right side diagram, each frontend is associated with its own backend. Each backend is responsible for calling the required downstream services.
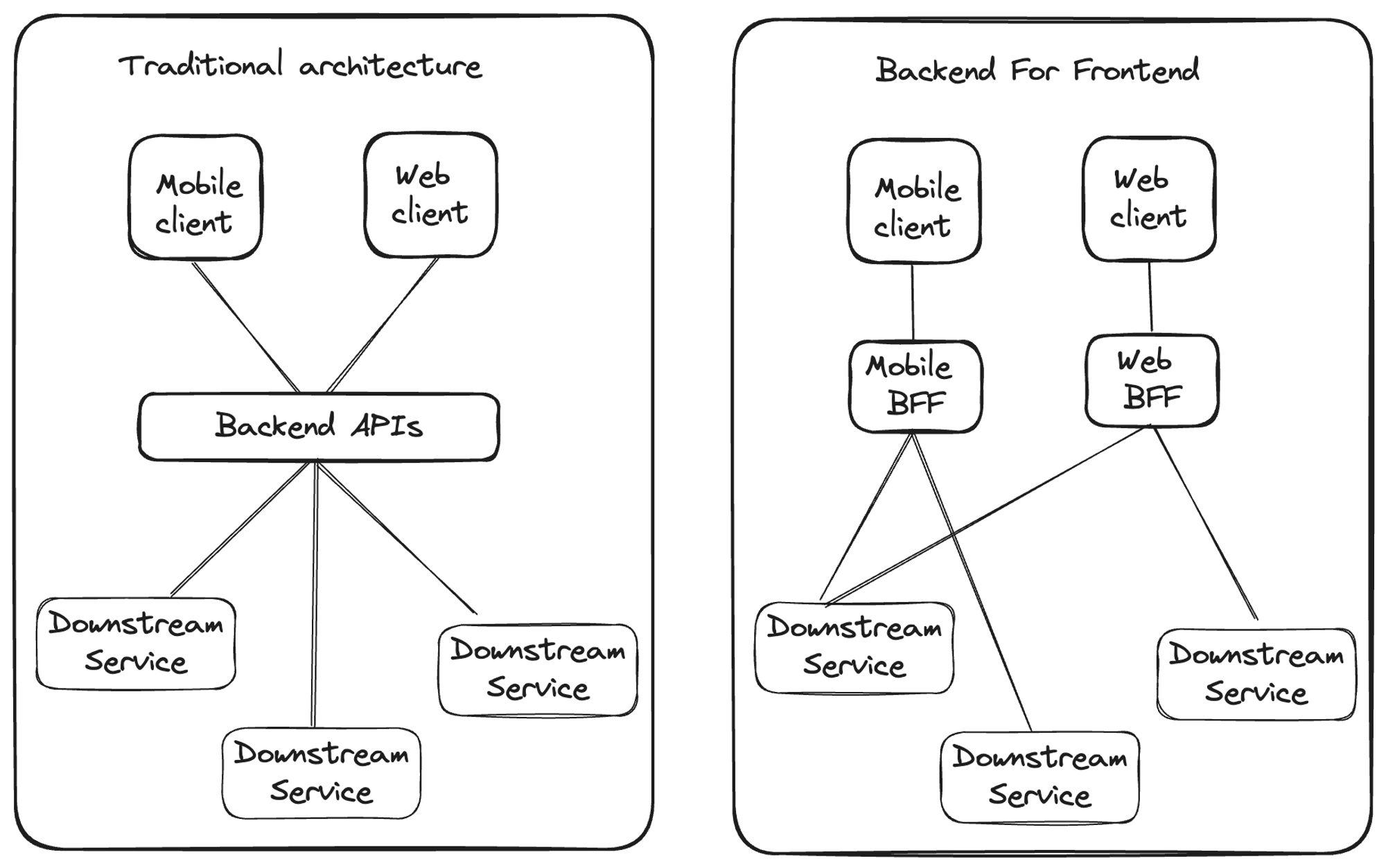
In traditional architecture, backend APIs can get bloated with client-specific requirements and API contracts can become cumbersome. On the other hand with BFF architecture, core backend services can expose robust client-agnostic APIs.
Product plays a big role in deciding a suitable architecture. In the following section we'll look at what is being built and then we'll continue.
The product
I’m currently working on building influencer marketing marketplace called Cogniplay. A place where influencers are matched with brands for influencer marketing campaigns. There are primarily two kinds of users on the platform. First influencers and second brands or agencies. Influencers use the platform to create their profile, showcase previous influencer marketing campaigns, and accept campaign orders whereas brands use it for launching campaigns & selecting influencers suitable for the campaigns.
The main difference between influencers as users and brands as users is that influencers prefer to access the website on a mobile browser whereas brands prefer a desktop web app. The information and experience that is expected by both these user types are completely different.
Right now the whole experience is powered by the web app but I can’t deny the possibility of having native apps in the future. This only means that each frontend will come with its own needs & expectations. Relying on a single backend to handle all requests would inevitably lead to complexities associated with managing client-specific logic.
Due to the above reasons, Backend For Frontend seemed like a suitable architecture.
Why NextJS?
NextJS is a framework built on top of ReactJS. One can write fullstack code in it. This fundamental property of NextJS makes it a suitable framework for the Backend for Frontend architecture. We’ll see some of the powerful features provided by NextJS.
Flexibility in Rendering Components
In a typical client-server web application, environments are divided by the network boundary. NextJS with the help of ReactJS features can render web applications on the server environment and the client environment. On the server side, there are various methods of rendering a web page. Mainly static compilation, server-side dynamic rendering, and streaming components progressively. Rendering on the client side is necessary in case of handling user interactions, and accessing browser APIs.
Unidirectional rendering:
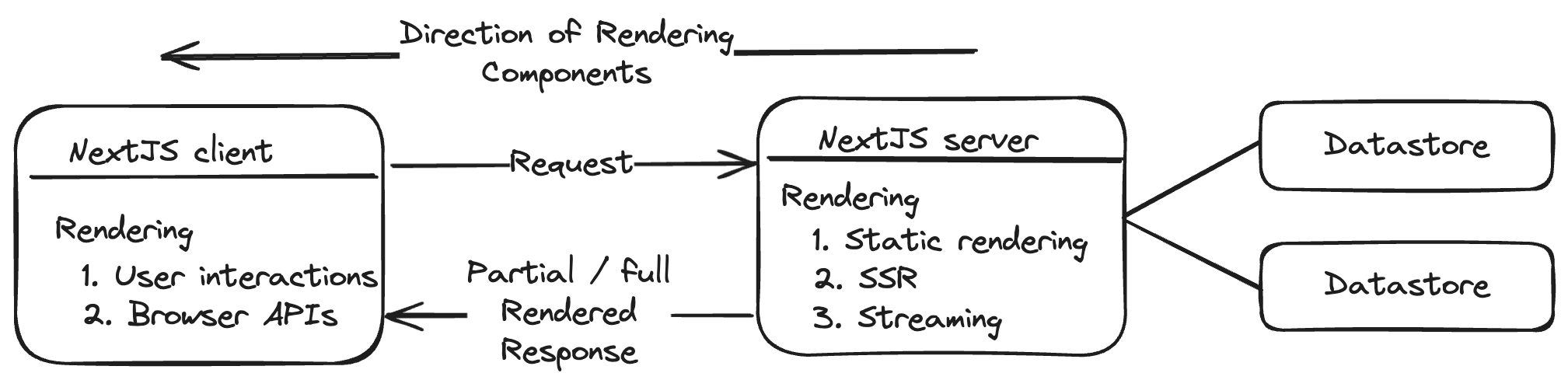
In NextJS, rendering happens in one direction. It starts from the server side and using various methods mentioned above either partially rendered components or fully rendered components are sent to the client to handle further rendering & interactions.
This unidirectional flow of rendering gives a good mental model for composing components to achieve hybrid rendering.
Caching
NextJS improves application’s performance & reduces cost by caching rendering work & data requests.
Request memoization:
React extends the fetch API to automatically memoize requests with identical URLs and options. This allows you to invoke a fetch function for the same data at multiple points within a React component tree, ensuring it's executed only once. This solves the common problem of passing props from parent components to child components. Fetch requests can be made multiple times without worrying about performance implications. Data is cached in memory till the completion of the request life cycle.
Data cache:
Unlike request memoization, data cache method persists the data in memory across multiple fetch requests. First-time fetch request misses the cache & hits the data store. Later fetch requests with same params hit the cache. It is an extension built by NextJS on top of fetch API.
Full route cache:
It is a server-side caching mechanism for routes that are statically & dynamically rendered. The rendering work is split into chunks of individual routes & suspense boundaries. Each chunk is rendered in two steps. React server component payload and HTML. RSC payload is a binary representation of React’s component tree & HTML is used to show the non-interactive preview of the page on client side. Eventually, the RSC payload is used to reconcile the DOM by calculating the diff. Javascript instructions are then used to hydrate components to make the application interactive.
Router cache:
Router cache temporarily stores the React Server Component payload per route in the browser for the duration of user session. It improves the performance of navigating between the pages.
Dealing with mutations
In a typical web application, mutations are mainly handled through forms & event handlers on buttons & links. These form submissions & event handlers make a network request to mutate data on the backend side. To deal with mutations, NextJS provides a feature called Server Actions.
Server Actions are nothing but asynchronous functions that can be invoked by passing as action attribute to the form or can be called by event handler. Since it is a function it can be reused anywhere in the application. It can also be passed as a prop to react component.
With the help of server actions, react features like useOptimistic & useFormState hooks, and libraries like Zod, developers can cover many cases like posting data, showing optimistic results, showing loading state & validating forms. These are the common cases one needs to handle when it comes to mutations.
Behind the scenes, server actions make a POST HTTP call and include security headers to prevent CSRF attacks.
Overall, NextJS gives a complete solution to build a fullstack application. It provides various techniques & powerful features. In this post, these powerful features can’t be covered in depth and most likely I’ll cover these in separate blog posts.
Next, we’ll look at how to setup a contract between the NextJS application & downstream services.
Simplifying contract between NextJS and Downstream services
For NextJS and downstream services to communicate, first we need to setup authentication & authorization contract. Depending on the requirement you can choose between Shared secret, API key, JWT token, etc. I wanted to begin with a simple system where downstream service would authenticate requests coming from the NextJS server. For this use case, I decided to use a shared secret.
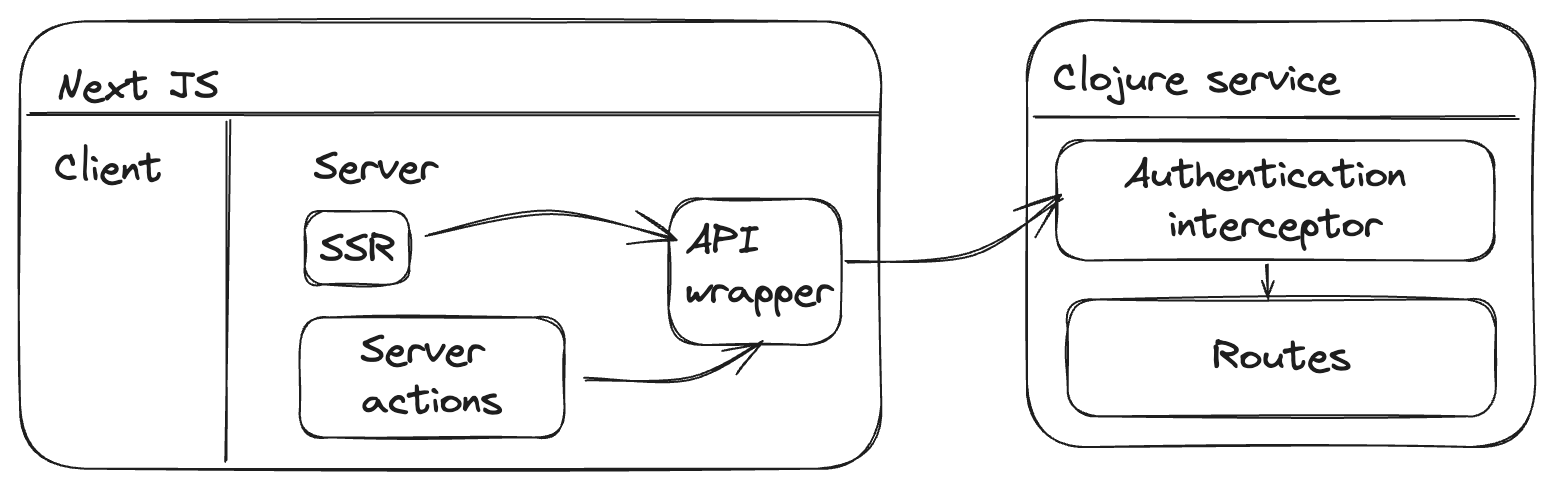
NextJS has different points from where it can call the downstream services. For example mostly GET requests would be called for rendering work. Server Actions would call POST, PUT, DELETE methods to mutate the state.
Rather than duplicating authentication code at multiple places, I've created a wrapper around downstream service APIs that take care of commonalities.
Following is sample API wrapper called from rendering components and Server Actions.
const BASE_URL = process.env.API_BASE_URL;
const HEADERS = {
"Content-Type": "application/json",
"X-API-Key": process.env.API_SHARED_SECRET as string,
};
interface QueryParams {
[key: string]: string | number | boolean;
}
async function get(url: string, queryParams?: QueryParams) {
const queryString = new URLSearchParams(
queryParams as Record<string, string>
).toString();
const fullUrl = `${BASE_URL}${url}${queryString ? "?" + queryString : ""}`;
return await fetch(fullUrl, {
headers: HEADERS,
cache: "no-store",
});
}
interface Opts {
method: string;
headers: Record<string, string>;
body?: string;
}
async function cud(method: string, url: string, body?: Object) {
const opts = {
method,
headers: HEADERS,
} as Opts;
if (body) {
opts.body = JSON.stringify(body);
}
return await fetch(`${BASE_URL}${url}`, opts);
}
async function post(url: string, body: Object) {
return await cud("POST", url, body);
}
async function put(url: string, body: Object) {
return await cud("PUT", url, body);
}
async function del(url: string, body?: Object) {
return await cud("DEL", url, body);
}
export async function createCampaignApi(userId: string, body: Object) {
return await post(`/campaigns/${userId}`, body);
}
export async function updateCampaignApi(
userId: string,
campaignId: string,
body: Object
) {
return await put(`/campaigns/${userId}/${campaignId}`, body);
}
export async function listCampaignApi(userId: string) {
return await get(`/campaigns/${userId}`);
}
export async function selectCampaignApi(userId: string, campaignId: string) {
return await get(`/campaigns/${userId}/${campaignId}`);
}
export async function deleteCampaignApi(userId: string, campaignId: string) {
return await del(`/campaigns/${userId}/${campaignId}`);
}
These asynchronous functions are then simply called to fetch data for completing the rendering work and doing mutations froms server actions.
Another Level of Indirection = RESTful APIs
All problems in computer science can be solved by another level of indirection (1)
We’ll take the example of rendering an influencer’s link in bio page. The page consists of the influencer’s information/bio (referenced as a user in the below code), auxiliary user details like Instagram, Youtube links (represented as a storefront in the below code), previous marketing campaigns, and payment details of the influencer.
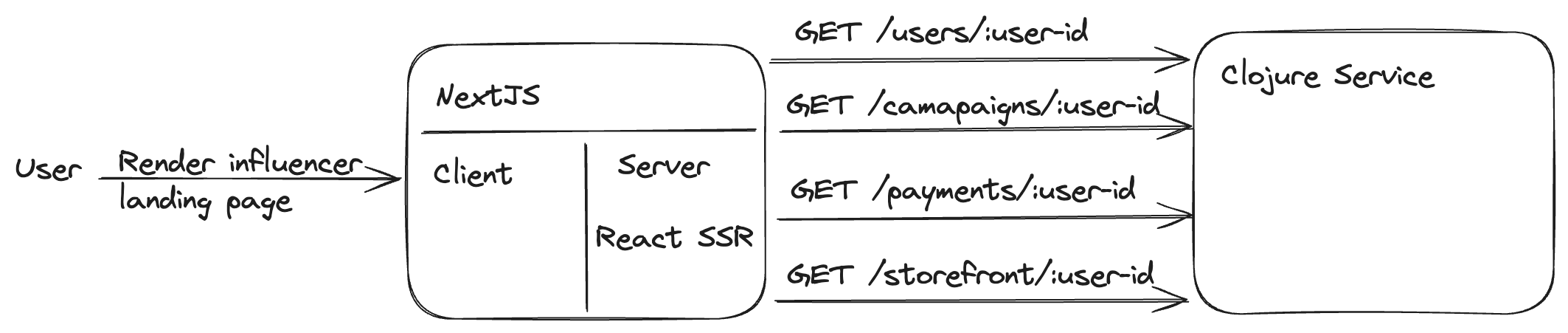
Clojure API routes:
(def routes
(route/expand-routes
#{["/echo" :get [echo]]
["/objects" :post (conj [(multipart-params) response->json] upload-object)]
["/objects" :delete (conj common-interceptors delete-object)]
["/users" :post (conj common-interceptors create-user)]
["/users/:user-id" :get (conj common-interceptors get-user)]
["/users/:user-id" :put (conj common-interceptors update-user)]
["/users/:user-id" :delete (conj common-interceptors delete-user)]
["/campaigns/:user-id" :post (conj common-interceptors create-campaign)]
["/campaigns/:user-id" :get (conj common-interceptors list-campaigns)]
["/campaigns/:user-id/:cid" :get (conj common-interceptors select-campaign)]
["/campaigns/:user-id/:cid" :put (conj common-interceptors update-campaign)]
["/campaigns/:user-id/:cid" :delete (conj common-interceptors delete-campaign)]
["/orders/:user-id" :post (conj common-interceptors create-order)]
["/orders/:user-id/:oid" :put (conj common-interceptors update-order)]
["/orders/:user-id" :get (conj common-interceptors list-orders)]
["/payments/:user-id" :post (conj common-interceptors authorize create-payment)]
["/payments/:user-id" :put (conj common-interceptors authorize update-payment)]
["/payments/:user-id" :get (conj common-interceptors authorize select-payment)]
["/storefront/:user-id" :post (conj common-interceptors create-storefront)]
["/storefront/:user-id" :get (conj common-interceptors select-storefront)]
["/storefront/:user-id" :put (conj common-interceptors update-storefront)]
["/storefront/:user-id" :delete (conj common-interceptors delete-storefront)]}))
As we can see the contract between NextJS and Clojure service is clean and comprehensible. There are no hacks or added complexities to handle client-specific logic.
All problems in computer science can be solved by another level of indirection. But that usually will create another problem (1)
The problem that it creates is every time user makes a request the cascading four routes are called putting more pressure on the Clojure service.
The good thing here is that NextJS heavily caches the data & server-rendered pages on both browser & the server side. So for a particular resource, the Clojure backend is hit only once in a while.



